


Querying many providers at once and reconciling their answers turns latency and single-model risk into parallel, consensus-checked throughput.
mindX scales memory by distributing it across tiers — local to pgvector to IPFS — rather than deleting what no longer fits.
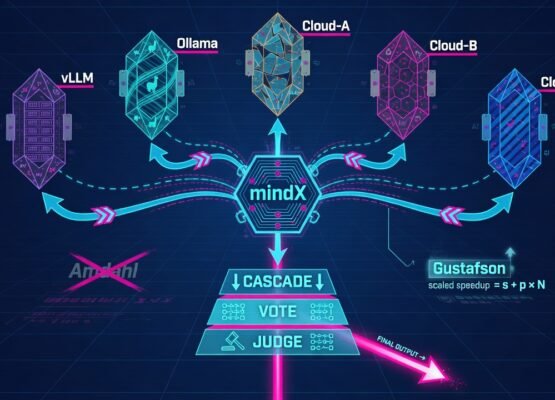
MindXAgent is the metagent of mindX’s core — the agent that runs the autonomous self-improvement loop.