Introduction: article created as first test of GPT-RESEARCHER as a research tool
The integration of Retrieval-Augmented Generative Engine (RAGE) with Large Language Models (LLMs) represents a significant advancement in the field of artificial intelligence, particularly in enhancing the reasoning capabilities of these models. This report delves into the application of RAGE in transforming LLMs into sophisticated reasoning agents, akin to a “MASTERMIND,” capable of strategic reasoning and intelligent decision-making. The focus is on how RAG facilitates this transformation by leveraging external knowledge bases, thereby enhancing the accuracy and depth of the LLMs’ outputs.
Understanding RAGE and LLMs
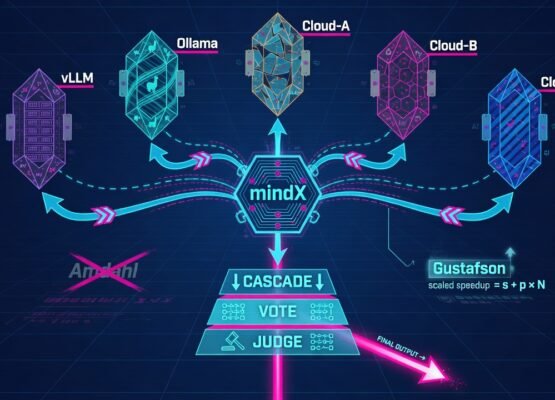
Retrieval-Augmented Generative Engine (RAGE) is a technique that enhances the performance of LLMs by incorporating external, authoritative knowledge bases prior to generating responses. This method allows LLMs to access up-to-date and relevant information, which significantly improves the accuracy and relevance of their outputs (Real Time News Analysis).
LLMs, such as GPT (Generative Pre-trained Transformer) and BERT (Bidirectional Encoder Representations from Transformers), are pre-trained on vast amounts of text data and are capable of generating human-like text based on the patterns they have learned. However, they often face challenges such as hallucination (generating plausible but incorrect or irrelevant information) and quickly becoming outdated as new information emerges.
RAGE’s Role in Enhancing LLMs
RAGE addresses these limitations by dynamically retrieving information from internal and external databases that are continually updated to create memory. This not only ensures the relevance and accuracy of the information provided by the LLMs but also significantly reduces the incidence of hallucinations. By integrating RAGE, LLMs can perform more effectively in knowledge-intensive tasks where precision and up-to-date knowledge are crucial (arXiv).
Strategic Reasoning with RAGE LLMs
Strategic reasoning involves understanding and predicting the actions of others in various scenarios, which is essential in fields such as business strategy, game theory, and negotiation. RAG-Enhanced LLMs can excel in these areas by accessing a wide range of scenarios and strategies stored in external databases, analyzing them, and generating strategic insights based on this data.
For instance, in multi-agent settings, a RAG-Enhanced LLM can predict competitors’ moves by accessing the latest market research reports or historical data on similar situations. This capability makes LLMs invaluable tools for strategic business analysis, policy formulation, and competitive strategy development.
Applications of RAG-Enhanced LLMs as MASTERMIND Agents
Business Strategy Formulation: By accessing and analyzing competitor data, market trends, and historical business outcomes, RAG-enhanced LLMs can help companies formulate strategies that are not only reactive but also proactive.
Negotiation and Diplomacy: In diplomatic negotiations, having access to historical treaties, negotiation tactics, and cultural nuances can significantly enhance the effectiveness of diplomats. RAG-enhanced LLMs can provide this information in real-time, helping negotiators make informed decisions.
Game Theory and Decision Making: In complex decision-making scenarios, such as those found in high-stakes trading or military strategy, RAG-enhanced LLMs can provide insights by retrieving and analyzing vast amounts of scenario-based data and previous outcomes.
Challenges and Future Directions
While RAGE significantly enhances the capabilities of LLMs, several challenges remain. These include the integration of real-time data feeds, the management of data privacy, and ensuring the unbiased retrieval of information. Future research could focus on improving the algorithms used for data retrieval to enhance the relevance and accuracy of the information provided. Additionally, more sophisticated methods for data privacy management need to be developed to ensure that the use of RAG-Enhanced LLMs adheres to ethical standards.
The integration of Retrieval-Augmented Generative Engine with Large Language Models holds significant promise for creating sophisticated reasoning agents capable of strategic thinking and decision-making. As this technology continues to evolve, it is expected to play a crucial role in various fields, enhancing the decision-making capabilities of AI systems and providing them with a competitive edge in strategic reasoning tasks.