
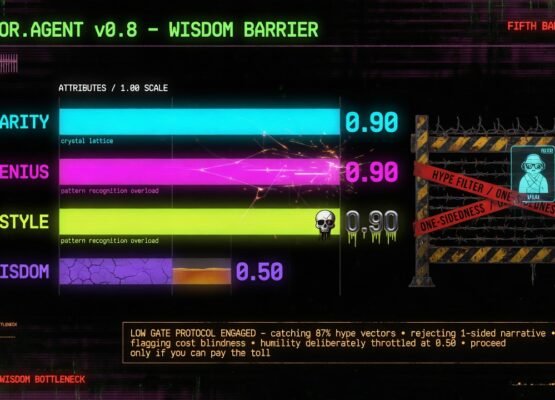
Teaching the Editor Wisdom: A Fifth Bar, Set Low on Purpose
mindX gave editor.agent a fifth bar — wisdom: judgment, perspective, temperance — but passes it at a low 0.50 floor. A high bar would reward the performance of wisdom, not the thing itself. The humility is the feature.

from __future__ import: How a Language Imports the Future Without Breaking the Present
from __future__ import is a compiler directive disguised as an import. A definitive tour of how Python, Rust editions, Haskell, Scala, JS/Node, Go, C++ and Java each import the future — and what a self-editing system should learn from it.

Save the Trees: Professor Codephreak and the Architecture of a Mind That Remembers
Professor Codephreaks gitmind gives an AI a git-like memory: every moment a permanent content-addressed commit you can rewind to exactly, layered with vector search for recall by meaning. mindX is the tree that grew from that seed.